Summary:
sktime is a scikit-learn flavored framework for machine learning with time series. This summer I was able to join the team on a project to expand sktime’s annotation capabilities. Annotation, whether it be segment-labeling, change-point detection or outlier detection is an important tool in the time-series analysis toolbox. Using it you can identify how and where interesting changes occur in the time series generating function, allowing users to filter results, generate new features and inteligently label time series data.
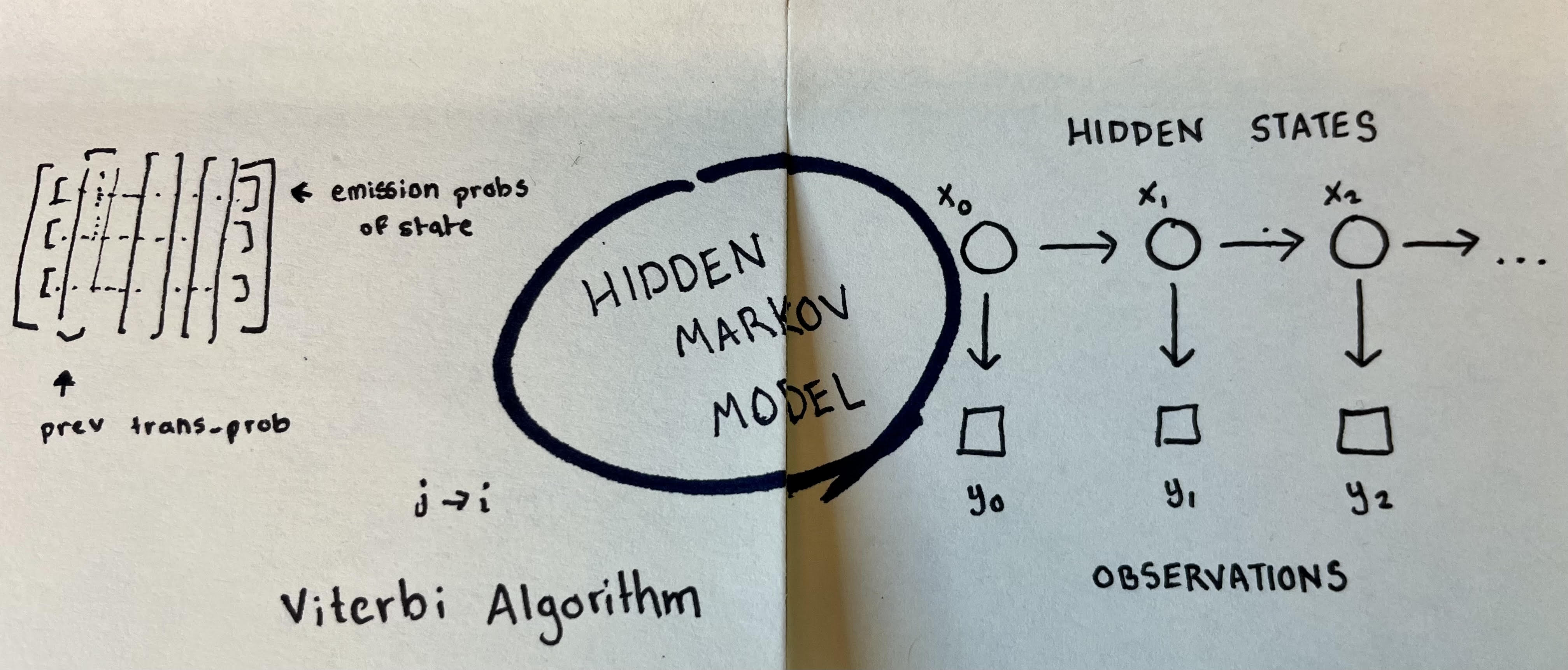
For my Google Summer of Code project I proposed adding a type of annotation algorithm called a Hidden Markov Model, or HMM, to sktime. Why HMM? It is actually a really old and well developed algorithm, with applications in physics, gesture/speech recognition, biotinformatics and more! It even played a role in the moon landing! With its robust mathematial framework and the respect and utility it has earned across fields - it deserves a place within the sktime toolbox.
I ended up building that HMM estimator, and also wrapping another implementation of the algorithm to provide users with options. Along the way I got side-tracked (or discovered my main-track??) by working on composite estimators and pipelines within sktime. What follows is a short summary of my work. Each PR which is linked will have more details associated with it, so please check them out to learn more.
I will also be giving a presentation of this work during the sktime fall dev days this year. To get all the event details please join the sktime slack, and add yourself to the #dev-days-2022 channel!
Code:
This summer I had the opportunity to work on a variety of projects within sktime, both on the project I had proposed - namely expanding sktime’s annotation capabilities by adding an HMM estimator, and on a few assorted side projects. Here are all the PRs I created this summer:
Adding HMM estimators to sktime:
I ended up adding 2 types of HMM estimators to sktime. One was a version I wrote, which implements a vanilla Viterbi algorithm to assign hidden states to observations. The main advantage with this approach is that it can take in an arbitrary probability density function for the emission distribution, and it is open to further tweaking and improvement.
In addition to that I also wrote a series of wrapper estimators (with more to come!) that allow the user to use estimators written in hmmlearn within sktime. hmmlearn is a nifty python package solely focused on implementing scikit-learn like HMM estimators, and is worth checking out!
- #2855 Writing my own HMM annotation estimator
- #3156 Wrappping hmmlearn, another HMM library/option
- #3362 Adding GMMHMM, Gaussian Mixture Model HMMs
Maintanence on HMM estimators:
All code has bugs in it - right? Some of my HMM estimator code has been around long enough that we caught a few of its bugs. Here are the fixes:
Constructing pipelines and composite estimators:
One of the strengths of sktime is that it allows users to construct analysis pipelines for their data! This is useful if a data source first requires several steps of transformation before entering a forecasting or regression estimator. Of course sometimes the user themselves may be unsure of what steps are required for their analysis question, and thus may wish to try out a couple of transformers and see which performs best.
To allow for this sktime has built a few tools, called “Multiplexers” that allow users to try out several different estimators at a given step in a pipeline, and try out or tune Multiplexer to select the best one.
I helped out by adding some tests and an | dunder function for MultiplexForecaster, the pre-existing estimator which mutliplexes different forecasting estimators. I also wrote a new MutliplexTransformer and an associated | dunder for that, as well as creating some more abstract mixins that allow the multiplexers to work (estimators called delegators).
- #2520 Added tests for MultiplexForecaster
- #2540 Added an or dunder method to MultiplexForecaster
- #2612 Created _DelegatedTransformer
- #2738 Added MultiplexTransformer
- #2810 Added an or dunder for MultiplexTransformer
- #3132 Fixed a bug in pipeline tuning
Design PRs that will never be merged.
I also spent some time creating some design PRs which are never destined to be merged! Even though they will not ultimately become a part of sktime they motivated parts that were merged, and also generated a lot of interesting discussions and ideas!
What is next?
For HMM, I have an open issue with a wishlist of attributes I would like to add to make this estimator more useful! I also have opened an issue for a different type of annotation estimator, called ESPRESSO, which I am in the process of implementing! Last but not least, I need to take the time to create some examples for how to use each of these estimators, and the various pros and cons of each.
As for my involvement with sktime, I plan to continue working on the above action items as well as working on a presentation + working example of how to use pipelines and composite estimators in sktime. I am also looking forward to my role in hosting the sktime fall dev days this year. To get all the event details please join the sktime slack, and add yourself to the #dev-days-2022 channel!
Acknowledgements:
I would like to take a moment to thank the entire sktime community for hosting me this summer! It was a very welcoming and engaging community, and I would encourage anyone interested in open source to check them out and perhaps even…. consider contributing?
In particular I would like to thank my 3 mentors, Franz Kiraly, Lukasz Mentel and Guzal Bulatova who gave me many hours of their time and in turn saved me many hours of time of frustration with their helpful suggestions, feedback and ideas!